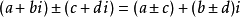模式识别算法
的有关信息介绍如下:
matlab 程序 http://www.cs.tut.fi/sgn/m2obsi/ex/kmeans.m 更多资源查看http://people.revoledu.com/kardi/tutorial/kMean/Resources.htm 帮你copy过来。 % kmeans.m : K-means clustering algorithm % Copyright (c) 2002 - 2003 % Jussi Tohka % Institute of Signal Processing % Tampere University of Technology % P.O. Box 553 FIN-33101 % Finland % jussi.tohka@tut.fi % ------------------------------- % Permission to use, copy, modify, and distribute this software % for any purpose and without fee is hereby % granted, provided that the above copyright notice appear in all % copies. The author and Tampere University of Technology make no representations % about the suitability of this software for any purpose. It is % provided "as is" without express or implied warranty. % ***************************************************************** % [c,costfunctionvalue, datalabels] = kmeans(data,k,c_init,max_iter) % Input: % data is the n x m matrix, where n is the number of data points % and m is their dimensionality. % k is the number of clusters % c_init is the initializations for cluster centres. This must be a % k x m matrix. (Optional, can be generated randomly). % max_iter is the maximum number of iterations of the algorithm % (Default 50). % Output: % c is the k x m matrix of final cluster centres. % costfunctionvalue is the value of cost function after each % iteration. % datalabels is a n x 1 vector of labeling of data. function [c,costfunctionvalue, datalabels,inter] = kmeans(data,k,varargin); datasize = size(data); n = datasize(1); m = datasize(2); if n < m fprintf(1,'Error: The number of datapoints must be greater than \n'); fprintf(1,'their dimension. \n'); return; end if length(varargin) > 0 c_init = varargin{1}; else % First, select k random numbers from 1 to n WITHOUT repetition randomindex = zeros(k,1); for i = 1:k randomindex(i) = unidrnd(n + 1 - i); randomindex(i) = randomindex(i) + sum(randomindex(1:i-1) <= ... randomindex(i)); end c_init = data(randomindex,:); end if size(c_init) ~= [k m]; fprintf(1,'Error: The size of c_init is incorrect.'); end if length(varargin) > 1 max_iter = varargin{2}; else max_iter = 50; end % Start the algorithm iter = 0; changes = 1; distances = zeros(n,k); costfunctionvalue = zeros(max_iter + 1,1); c = c_init; datalabels = zeros(n,1); while iter < max_iter & changes iter = iter + 1; fprintf(1,'#'); old_datalabels = datalabels; % Compute the distances between cluster centres and datapoints for i = 1:k dist(:,i) = sum((data - repmat(c(i,:),n,1)).^2,2); end % Label data points based on the nearest cluster centre [tmp,datalabels] = min(dist,[],2); % compute the cost function value costfunctionvalue(iter) = sum(tmp); % calculate the new cluster centres for i = 1:k c(i,:) = mean(data(find(datalabels == i),:)); end % study whether the labels have changed changes = sum(old_datalabels ~= datalabels); inter(iter).datalabels = datalabels; inter(iter).c = c; end for i = 1:k dist(:,i) = sum((data - repmat(c(i,:),n,1)).^2,2); end [tmp,datalabels] = min(dist,[],2); % compute the cost function value costfunctionvalue(iter + 1) = sum(tmp); fprintf(1,'\n');希望对您有所帮助